

Archiving your own internet
Don't let the internet rot around you!!

One of the recurring disappointments of my life is reading decade-old SSC posts, clicking on a link, and getting greeted by a 404. Linkrot is especially relevant when you're a prolific author with little regard for building carefully constructed libraries. SSC posts fade and fall apart: their “internet weight”—the linked context you can access easily—decays quickly. It feels like reading about the work of Celsus, a man known exclusively through a single work of criticism against him. For example the SSC post In Favor of Niceness, Community and Civilization is a quote-by-quote refutation of a lost Facebook rant by “Andrew Cord", itself sparsely backed up on a post that is now a 404.
SSC might not be a great example: Scott Alexander's audience is large and CS-literate, such that it's likely most outlinks got backed up at some point. But what of lesser-known authors of the time, who may yet experience a renaissance in history grad student dorms? Texts from antiquity are heavily selected for being relevant to Christianity, given medieval monk triage habits. SSC being an outlier among blogs in its time doesn't mean smaller blogs won't be prized as lost jewels in the future, depending on the future's new selection criteria. What of their internet weight?
Well, you build whatever monster automation Gwern built for himself on Gwern.net. Opus 4.7 made a comparison site for these two:
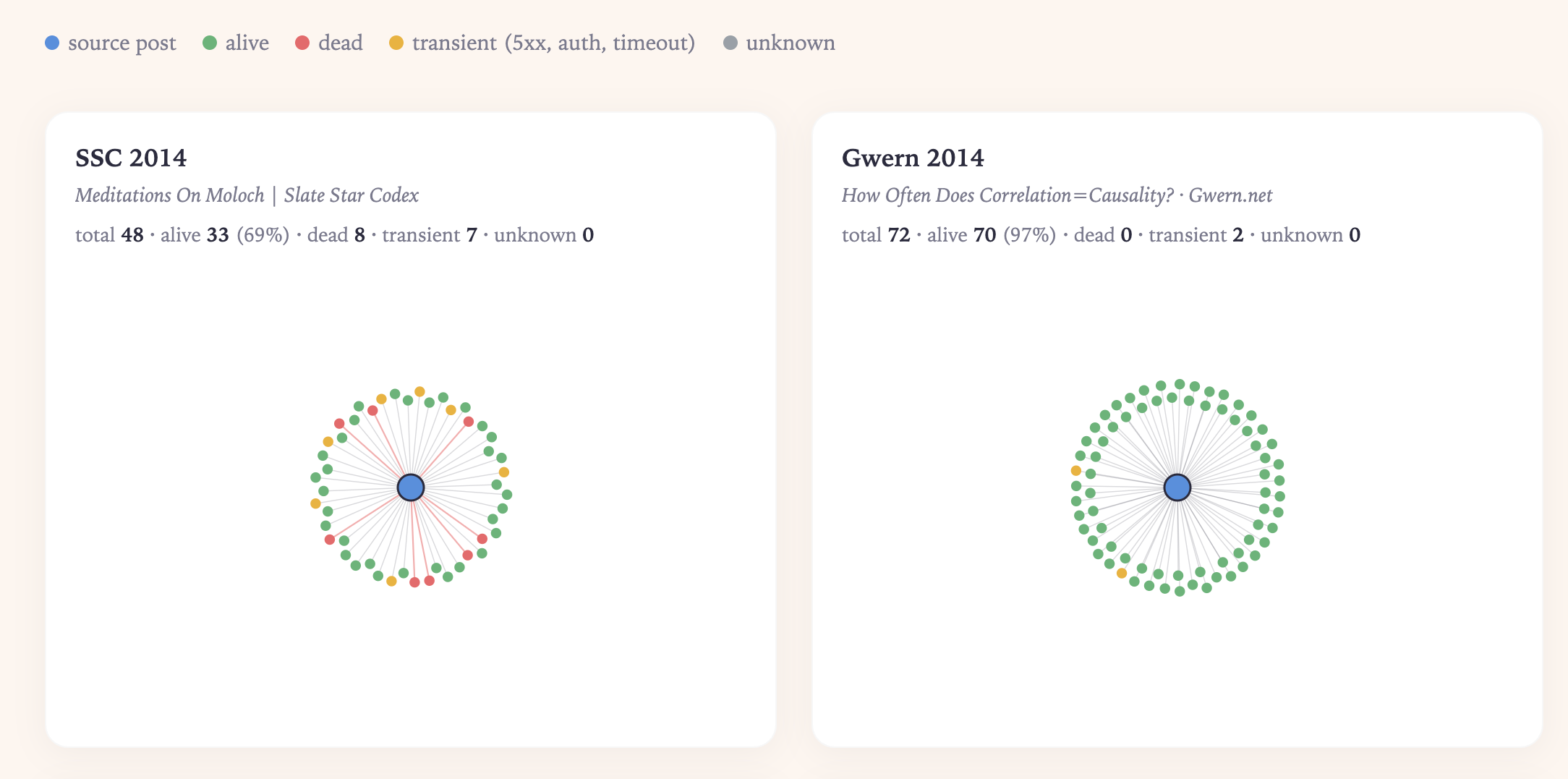
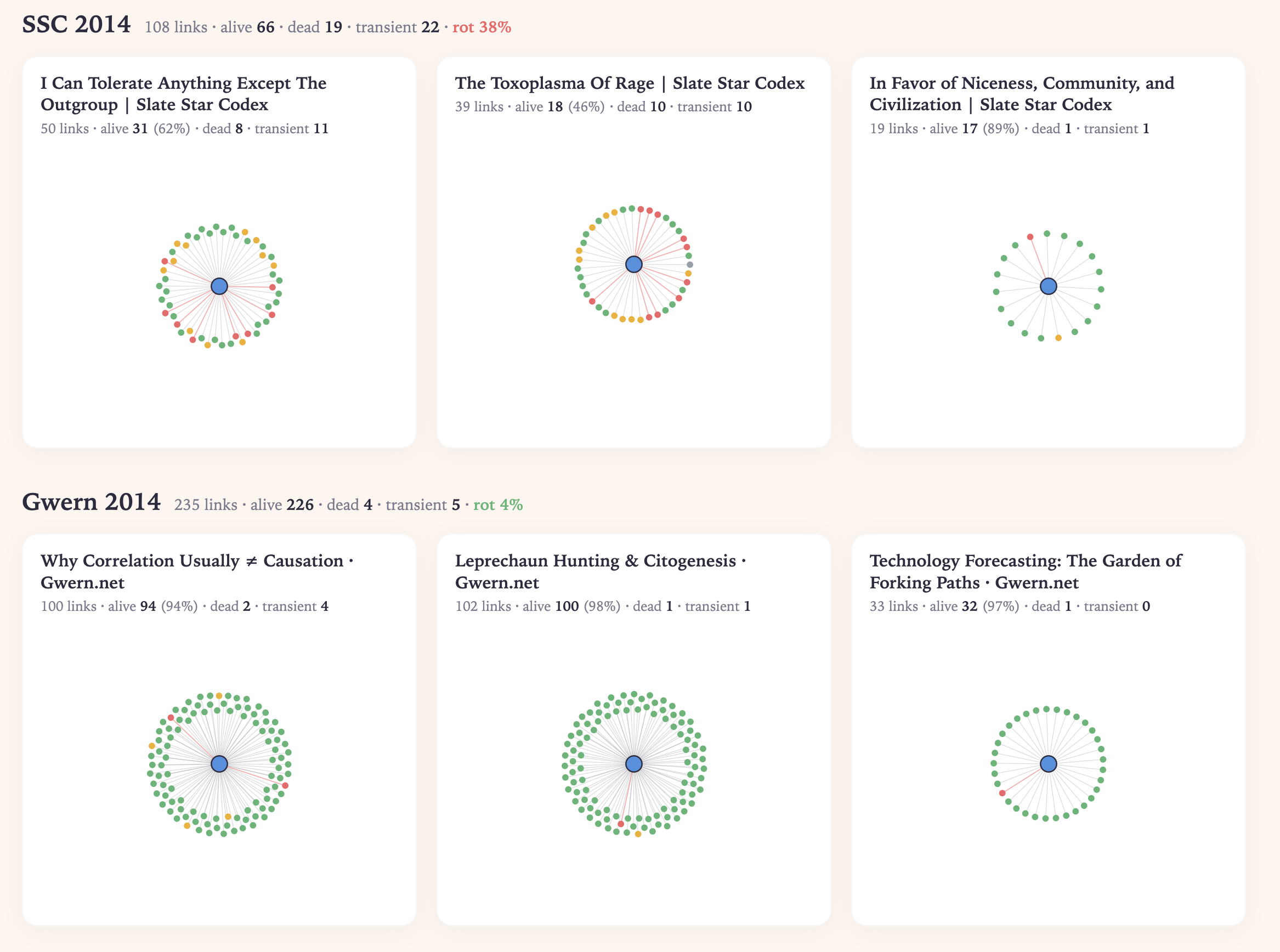
Scott lets his posts undergo an order of magnitude more rot! This follows from the two men's respective philosophies: Gwern wants a “long site”, and several of his posts took him years to write, like making a layered renaissance painting. Meanwhile Asterisk editor Clara Collier told me Scott's the only person she knows who requires zero editing after banging out a post and essentially never re-reads his work. Historically, SSC posts were written in between appointments at his hospital and were not his “main thing” like they were for Gwern. Gwern is humble with his explanations for himself, while Scott basically offers “I don't understand why people find it hard to write. They can talk right? Isn't writing just like talking?"
But this doesn't make SSC archiving less important for historians. So much of our literary corpus was never treated with respect by its own authors. You needn’t want to build a cathedral to be doing it anyway.1
So systematic solutions to back up your outlinks and update them to backups are rare, but definitely a good idea for the health of our internet. You could figure out what Gwern and Achmiz did in their code base or you could use this code Claude made that lives in your macbook terminal and should be simple to set up:
https://github.com/Croissanthology/croissanthology.github.io/tree/main/archiver
The easiest way, as always, is just asking Claude in the CLI to do it! Anyway here's a little preview:

See Les Pensées by Pascal, a collection of loose index cards we found after his death. Among other gems one of my favorite paragraphs ever:
L’homme n’est qu’un roseau, le plus faible de la nature, mais c’est un roseau pensant. Il ne faut pas que l’univers entier s’arme pour l’écraser ; une vapeur, une goutte d’eau suffit pour le tuer. Mais quand l’univers l’écraserait, l’homme serait encore plus noble que ce qui le tue, puisqu’il sait qu’il meurt et l’avantage que l’univers a sur lui. L’univers n’en sait rien.
A quarter of Leonardo Da Vinci's notebook pages survive to this day, and they're crammed with fun ideas and drawings (I'd recommend buying a copy!) They're a scribbled mess, but they rival his 2 magnum opera (as we tend to regard them) in how much our civilization cherishes them.
Marcus Aurelius similarly wrote to himself in a journal self-improvement bros can buy at any airport. People know him today by Meditations more than by whatever his track record was as emperor of Rome.
Cicero describes Aristotle's public-intended works and prose as “a golden river", but essentially all of it was lost. Aristotle is remembered by his working documents, lecture notes, and treatises addressed to faculty, not anything he intended for posterity.
Darwin called Origin an “abstract", by which he meant a hurried summary meant to secure credit for the idea before Wallace could swoop in.
Virgil and Kafka were betrayed posthumously by friends who refused to burn their work as instructed.
I've been eyeing ArchiveBox [ https://archivebox.io/ ] for a while now. When I first came across it I was worried about affording the storage space, but also when I first came across it I was very poor, and I *could* buy more storage now.
---
I *am* in the habit of using grab-site (and later browsertrix-crawler: the 2026 Internet is less friendly to scrapers than even 2024, and browsertrix-crawler is better at getting around this) on my own blogs and on sites that I otherwise particularly like, and I have the Internet Archive extension installed and keep an eye out for pages marked with a 0. (*Don't* turn on automatic uploads, or you'll get fucked whenever you find out too late that a site was still using URL security-by-obscurity. I speak from personal experience.)
Come to think of it, I wonder if the increased anti-scrape measures on the post-LLM Internet are giving your rot counter some false(-ish) positives. Like, you can't naively scrape Tumblr at all anymore: if you're not using anti-anti-scrape, it will appear as if the site no longer exists.
---
I'm surprised that I'm the first person to notify the Wayback Machine about this post.